
简介
1、HBase是Apache Hadoop的数据库,能够对大型数据提供随机、实时的读写访问,是Google的BigTable的开源实现。
2、HBase的目标是存储并处理大型的数据,更具体地说仅用普通的硬件配置,能够处理成千上万的行和列所组成的大型数据库。
3、HBase是一个开源的、分布式的、多版本的、面向列的存储模型。可以直接使用本地文件系统,也可使用Hadoop的HDFS文件存储系统。
为了提高数据的可靠性和系统的健壮性,并且发挥HBase处理大型数据的能力,还是使用HDFS作为文件存储系统更佳。
另外,HBase存储的是松散型数据,具体来说,HBase存储的数据介于映射(key/value)和关系型数据之间。如下图所示,HBase存储的数据从逻辑上看就是一张很大的表,并且它的数据列可以根据需要动态增加。每一个cell中的数据又可以有多个版本(通过时间戳来区别),从下图来看,HBase还具有 " 向下提供存储,向上提供运算 " 的特点。
HBase体系结构
HBase的服务器体系结构遵从简单的主从服务器架构,它由HRegion Server群和HBase Master服务器构成。
HBase Master负责管理所有的HRegion Server,而HBase中的所有RegionServer都是通过ZooKeeper来协调,并处理HBase服务器运行期间可能遇到的错误。
HBase Master Server本身并不存储HBase中的任何数据,HBase逻辑上的表可能会被划分成多个Region,然后存储到HRegion Server群中。HBase Master Server中存储的是从数据到HRegion Server的映射。因此HBase体系结构如下图所示:
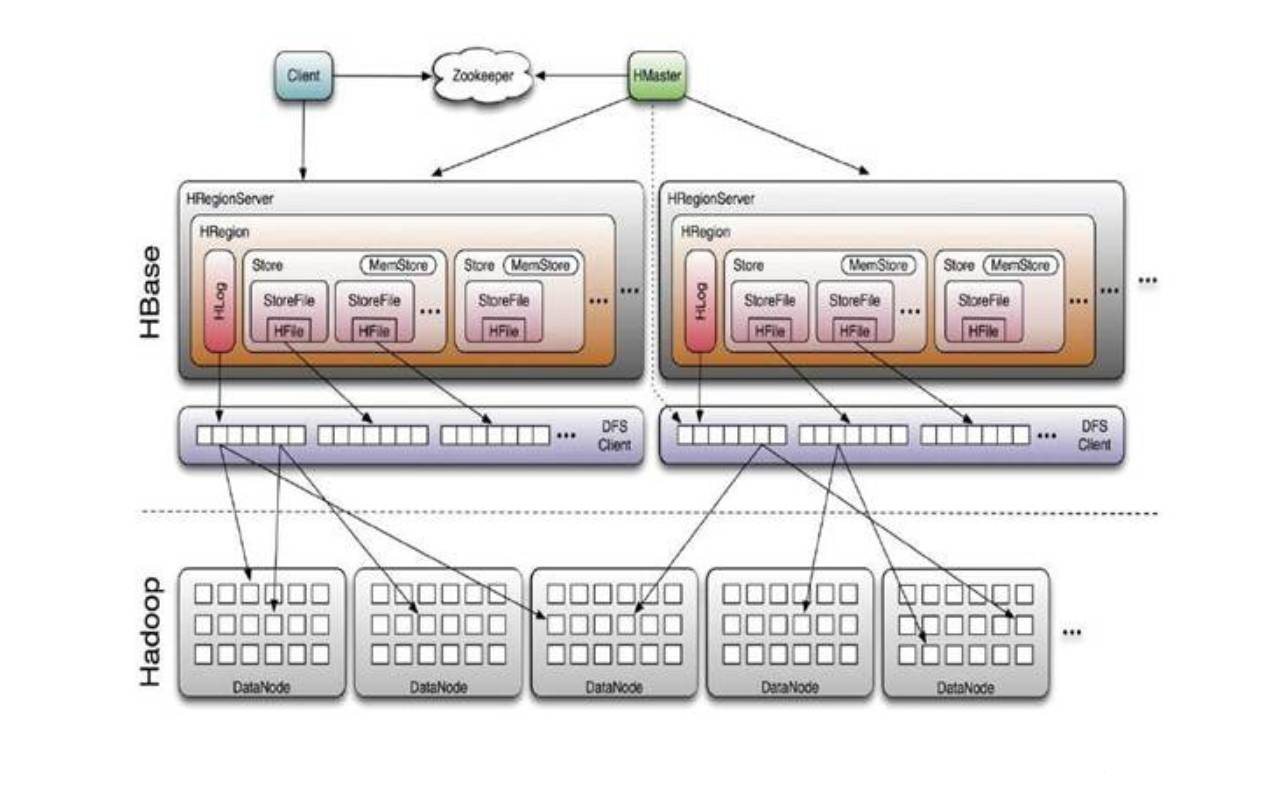
1 Client
HBase Client 使用HBase的RPC机制与HMaster和HRegionServer进行通信:对于管理类操作,Client与HMaster进行RPC;对于数据读写类操作,Client与HRegionServer进行RPC;
2 Zookeeper
Zookeeper Quorum中除了存储了-ROOT-表的地址和HMaster的地址,HRegionServer也会把自己以Ephemeral方式注册到 Zookeeper中,使得HMaster可以随时感知到各个HRegionServer的健康状态。此外,Zookeeper也避免了HMaster的 单点问题;
3 HMaster
每台HRegionServer都会与HMaster进行通信,HMaster的主要任务就是要告诉每台HRegion Server它要维护哪些HRegion。
当一台新的HRegionServer登录到HMaster时,HMaster会告诉它等待分配数据。而当一台HRegion死机时,HMaster会把它负责的HRegion标记为未分配,然后再把它们分配到其他的HRegion Server中。
HBase已经解决了HMaster单点故障问题(SPFO),并且HBase中可以启动多个HMaster,那么它就能够通过Zookeeper来保证系统中总有一个Master在运行。HMaster在功能上主要负责Table和Region的管理工作,具体包括:
1、管理用户对Table表的增、删、改、查操作;
2、管理HRegion服务器的负载均衡,调整HRegion分布;
3、在HRegion分裂后,负责新HRegion的分配;
4、在HRegion服务器停机后,负责失效HRegion服务器上的HRegion迁移。
4 HRegion
当表的大小超过设置值得时候,HBase会自动地将表划分为不同的区域,每个区域包含所有行的一个子集。对用户来说,每个表是一堆数据的集合,靠主键来区分。从物理上来说,一张表被拆分成了多块,每一块就是一个HRegion。我们用表名+开始/结束主键来区分每一个HRegion,一个HRegion会保存一个表里面某段连续的数据,从开始主键到结束主键,一张完整的表格是保存在多个HRegion上面。
- 管理用户对Table的增删改查操作
- 管理HRegionServer的负载均衡,调整Region分布
- 在Region Split后,负责新Region的分配
- 在HRegionServer停机后,负责失效HRegionServer上的Region迁移
5 HRegionServer
HRegionServer主要负责响应用户I/O请求,向HDFS文件系统中读写数据,是HBase中最核心的模块。
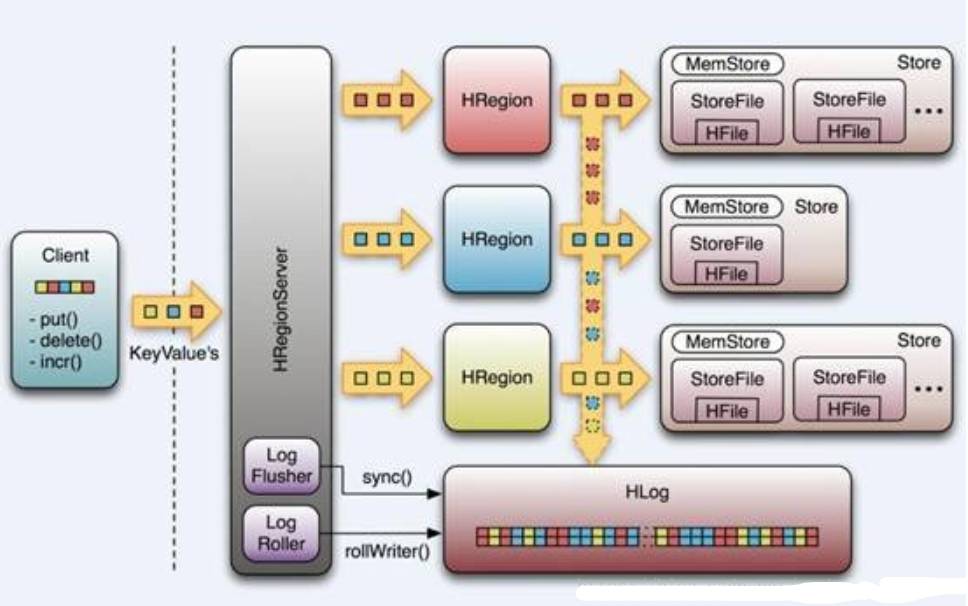
HRegionServer内部管理了一系列HRegion对象,每个HRegion对应了Table中的一个 Region,HRegion中由多个HStore组成。每个HStore对应了Table中的一个Column Family的存储,可以看出每个Column Family其实就是一个集中的存储单元,因此最好将具备共同IO特性的column放在一个Column Family中,这样最高效。
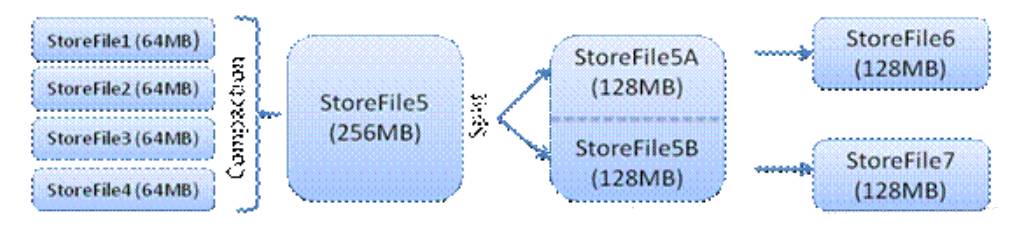
HStore存储是HBase存储的核心,其中由两部分组成,一部分是MemStore,一部分是StoreFiles。 MemStore是Sorted Memory Buffer,用户写入的数据首先会放入MemStore,当MemStore满了以后会Flush成一个StoreFile(底层实现是HFile), 当StoreFile文件数量增长到一定阈值,会触发Compact合并操作,将多个StoreFiles合并成一个StoreFile,合并过程中会进行版本合并和数据删除,因此可以看出HBase其实只有增加数据,所有的更新和删除操作都是在后续的compact过程中进行的,这使得用户的写操作只要 进入内存中就可以立即返回,保证了HBase I/O的高性能。当StoreFiles Compact后,会逐步形成越来越大的StoreFile,当单个StoreFile大小超过一定阈值后,会触发Split操作,同时把当前 Region Split成2个Region,父Region会下线,新Split出的2个孩子Region会被HMaster分配到相应的HRegionServer 上,使得原先1个Region的压力得以分流到2个Region上。
下图描述了Compaction和Split的过程:
理解上述HStore的基本原理之后,必须了解一下HLog的功能,因为上述的HStore在系统正常工作的前提下是没有问题的,但是在分布式系统环境中,无法避免系统出错或者宕机,一次一旦HRegion Server意外退出,MemStore中的内存数据将会丢失,这就需要引入HLog了。每一个HRegionServer中都有一个HLog对象,HLog是一个实现Write Ahead Log的类,在每次用户操作写入MemStore的同时,也会写一份数据到HLog文件中,HLog文件定期会滚动出新的,并删除旧的文件,当HRegionServer意外终止后,HMaster会通过Zookeeper感知到,HMaster首先会处理遗留的HLog文件,将其中不同Region的Log数据进行拆分,分别放到相应Region的目录下,然后再将失效的Region重新分配,领取到这些Region的HRegionServer在LoadRegion过程中,会发现有历史HLog需要处理,因此会Replay HLog中的数据到MemStore中,然后flush到StoreFiles,完成数据恢复
您可以选择一种方式赞助本站
支付宝扫一扫赞助
微信钱包扫描赞助
赏