
一个无向图G的最小生成树就是由该图的那些连接了G的所有顶点的边构成的树,且其总权重最低。最小生成树存在当且仅当G是连通的。
对于任何一生成树T,如果将一条不属于T的边e加进来,则产生一个圈。如果从圈中除去任意一条边,则又恢复树的特性。如果边e的权值比除去的边的值低,那么新生成的树的值就比原生成的树的值低。如果在建立树T的过程中每次添加的边在所有避免成圈的边中值最小,那么最后得到的生成树的值不能再改进。对于最小生成树的贪婪算法是成立的。
算法策略
在每一个步骤中都形成最小生成树的一条边。算法维护一个边的集合A,保持以下的循环不变式:
在每一次循环迭代之前,A是某个最小生成树的一个子集。
在算法的每一步中,确定一条边(u,v),使得它加入到A后,仍然不违反这个循环不变式,即A与{(u,v)}的并集仍然是某一个最小生成树的子集。称这样的边为A的安全边。
根据确定安全边的方法,有两种最小生成树算法:
Prim算法
使最小生成树一步步成长,每一步都把一个节点当做根并往上加边。在算法的任一时刻,都可以看到一个已添加到树上的顶点集。每一阶段,选择一条边(u,v)使得此条边的权值是所有u在树上但v不在树上的边的值中的最小者。对每一个顶点保留值dv和pv,dv是连接顶点v到已加入树上的顶点集的最短边的权,pv是导致dv改变的最后的顶点。可见Prim算法基本上和Dijkstra算法基本是一样的,只是dv定义有所不同,在Dijkstra算法中dv是v到源点的最短边。
一个互联网广播的例子:
将所有顶点加入到队列Q中:
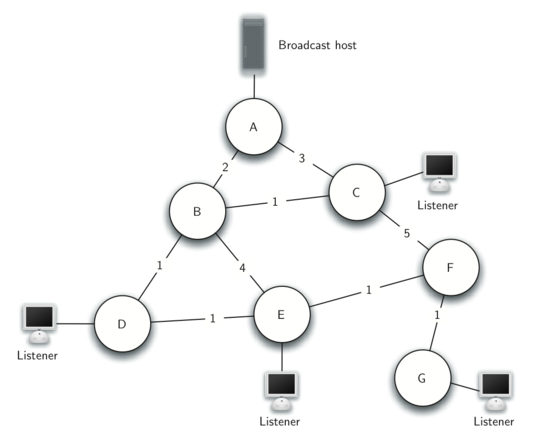
将A选为源点,A出队列Q,加入到树T中,更新B,C的d值:
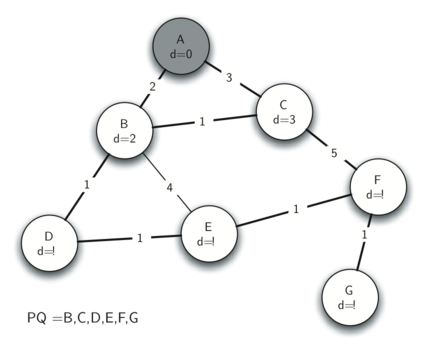
最小边为(A,B),将B移出Q,加入到树T中,更新CDE的d值
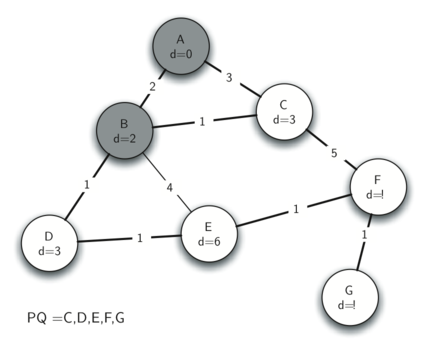
以此类推,得到结果:
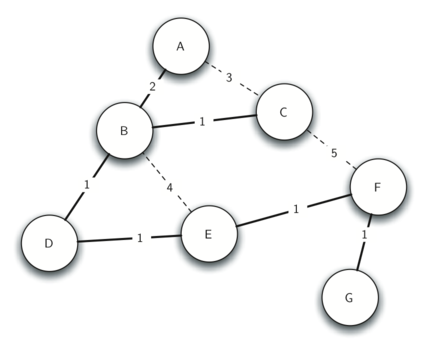
代码
def Prim(G,s):
path={}
pre={}
alist=[]
for v in G:
alist.append(v)
path[v]=sys.maxsize
pre[v]=s
path展开=0
queue=PriorityQueue(path)
queue.buildHeap(alist)
while queue.size>0:
vertex=queue.delMin()
for v in vertex.getNeighbors():
newpath=vertex.getWeight(v)
if v in queue.queue and newpath<path[v]:
path[v]=newpath
pre[v]=vertex
queue.perUp(v)
return pre
if __name__=='__main__':
g= Graph()
g.addEdge('a','b',2)
g.addEdge('b','a',2)
g.addEdge('a','c',3)
g.addEdge('c','a',3)
g.addEdge('b','c',1)
g.addEdge('c','b',1)
g.addEdge('b','d',1)
g.addEdge('d','b',1)
g.addEdge('d','e',1)
g.addEdge('e','d',1)
g.addEdge('b','e',4)
g.addEdge('e','b',4)
g.addEdge('c','f',5)
g.addEdge('f','c',5)
g.addEdge('e','f',1)
g.addEdge('f','e',1)
g.addEdge('f','g',1)
g.addEdge('g','f',1)
u=g.getVertex('a')
path=Prim(g,u)
for v in path:
print v.id,' after ',path[v].id
输出:
a after a
b after a
c after b
d after b
e after d
f after e
g after f
Prim算法是在无向图上运行的,记住把每一条边都加入到两个邻接表中。不用堆时运行时间为O(|V|2),使用二叉堆的运行时间是O(|E|log|V|)。
Kruskal算法
连续的按照最小的权选择边,并且在当所选的边不产生圈时把它作为选定的边。形式上Kruskal算法是在处理一个森林——树的集合,该算法找出森林中连接任意两棵树的所有边中,具有最小权值的边作为安全边。一开始,存在|V|棵单节点树,添加边则将两棵树合并为一棵树。算法终止的时候就剩下一棵树了,这棵树就是最小生成树。此算法用不相交集合的Union/Find算法确定安全边。对于一条边(u,v),如果u和v在同一集合中,那么就要放弃此边,因为他们已经连通了,再添加此边就会形成一个圈。
选取边时可以根据边的权值将边排序,然后从小到大选取边,不过建堆是更好的想法。
class Vertex(object):
def __init__(self,key):
self.id=key
self.adj={}
self.parent=None
self.rank=0
def addNeighbor(self,nbr,weight=0):
self.adj[nbr]=weight
def getNeighbors(self):
return self.adj.keys()
def getId(self):
return self.id
def getWeight(self,key):
return self.adj[key]
def Kruskal(G):
elist=[]
accpeted_e_list=[]
for v in G:
for vertex in v.getNeighbors():
e=Edge(v,vertex,v.getWeight(vertex))
elist.append(e)
queue=KruskalQueue(elist)
queue.buildHeap()
edge_num=0
while edge_num<G.size-1:
e=queue.delMin()
u=e.u
v=e.v
uset=Find(u)
vset=Find(v)
if uset!=vset:
accpeted_e_list.append(e)
edge_num+=1
Union(uset,vset)
return accpeted_e_list
class Edge(object):
def __init__(self,u,v,weight):
self.u=u
self.v=v
self.weight=weight
class KruskalQueue(object):
def __init__(self,elist):
self.elist=elist
self.size=len(self.elist)
def buildHeap(self):
for i in xrange(self.size/2-1,-1,-1):
self.perDown(i)
def delMin(self):
self.elist[0],self.elist[-1]=self.elist[-1],self.elist[0]
e=self.elist.pop()
self.size-=1
self.perDown(0)
return e
def perDown(self,i):
left=2*i+1
right=2*i+2
little=i
if left<=self.size-1 and self.elist[i].weight>self.elist[left].weight:
little=left
if right<=self.size-1 and self.elist[little].weight>self.elist[right].weight:
little=right
if little!=i:
self.elist[i],self.elist[little]=self.elist[little],self.elist[i]
self.perDown(little)
def perUp(self,i):
if i>0 and self.elist[i].weight<self.elist[(i-1)/2].weight:
self.elist[i],self.elist[(i-1)/2]=self.elist[(i-1)/2],self.elist[i]
self.perUp((i-1)/2)
def Find(v):
if v.parent is None:
return v
else:
v.parent=Find(v.parent)
return v.parent
def Union(u,v):
if u.rank<=v.rank:
u.parent=v
if u.rank==v.rank:
v.rank+=1
else:
v.parent=u
if __name__=='__main__':
g= Graph()
g.addEdge('a','b',2)
g.addEdge('a','c',3)
g.addEdge('b','c',1)
g.addEdge('b','d',1)
g.addEdge('d','e',1)
g.addEdge('b','e',4)
g.addEdge('f','c',5)
g.addEdge('f','e',1)
g.addEdge('g','f',1)
elist=Kruskal(g)
for e in elist:
print 'edge(%s,%s)'%(e.u.id,e.v.id)
输出:
>>> edge(b,c) edge(f,e) edge(b,d) edge(g,f) edge(d,e) edge(a,b)
算法的最坏情况是O(|E|log|E|),受堆操作控制。图稠密的时候,E=O(V2),实际运行时间为O(ElogV)。
您可以选择一种方式赞助本站
支付宝扫一扫赞助
微信钱包扫描赞助
赏