
为什么需要 service
service 的工作原理

endpoints controller 是负责生成和维护所有 endpoints 对象的控制器,监听 service 和对应 pod 的变化,更新对应 service 的 endpoints 对象。当用户创建 service 后 endpoints controller 会监听 pod 的状态,当 pod 处于 running 且准备就绪时,endpoints controller 会将 pod ip 记录到 endpoints 对象中,因此,service 的容器发现是通过 endpoints 来实现的。而 kube-proxy 会监听 service 和 endpoints 的更新并调用其代理模块在主机上刷新路由转发规则。
service 的负载均衡
上文已经提到 service 实际的路由转发都是由 kube-proxy 组件来实现的,service 仅以一种 VIP(ClusterIP) 的形式存在,kube-proxy 主要实现了集群内部从 pod 到 service 和集群外部从 nodePort 到 service 的访问,kube-proxy 的路由转发规则是通过其后端的代理模块实现的,kube-proxy 的代理模块目前有四种实现方案,userspace、iptables、ipvs、kernelspace,其发展历程如下所示:
-
kubernetes v1.0:services 仅是一个“4层”代理,代理模块只有 userspace
-
kubernetes v1.1:Ingress API 出现,其代理“7层”服务,并且增加了 iptables 代理模块
-
kubernetes v1.2:iptables 成为默认代理模式
-
kubernetes v1.8:引入 ipvs 代理模块
-
kubernetes v1.9:ipvs 代理模块成为 beta 版本
-
kubernetes v1.11:ipvs 代理模式 GA
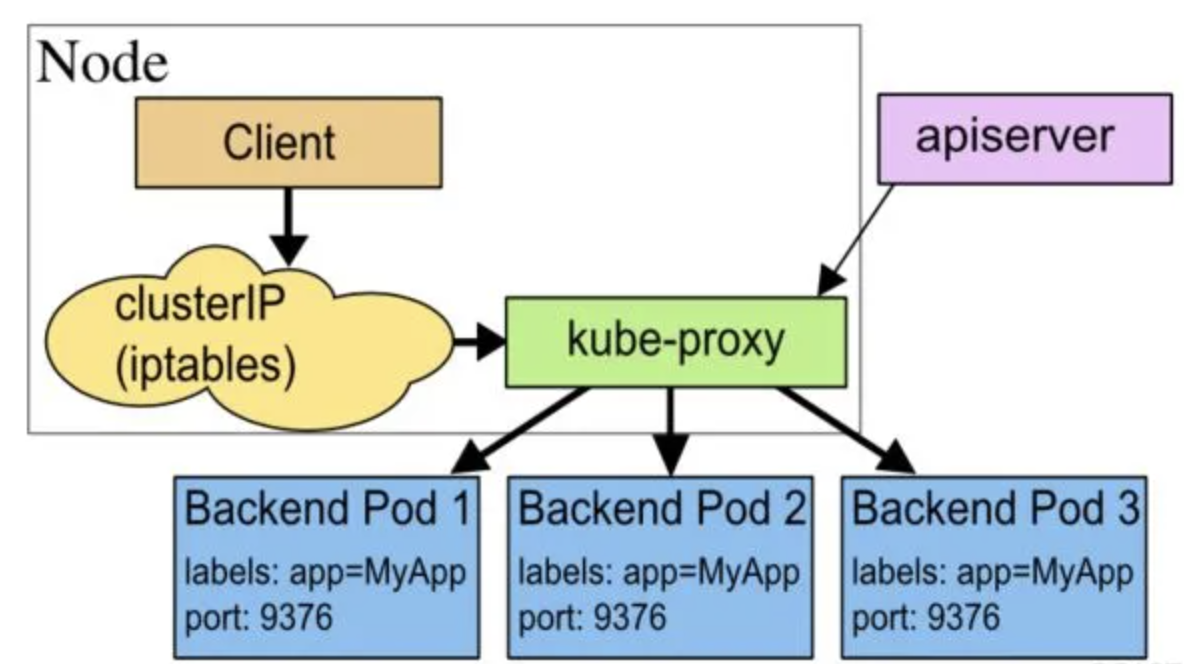
userspace 模式
在 userspace 模式下,访问服务的请求到达节点后首先进入内核 iptables,然后回到用户空间,由 kube-proxy 转发到后端的 pod,这样流量从用户空间进出内核带来的性能损耗是不可接受的,所以也就有了 iptables 模式。
为什么 userspace 模式要建立 iptables 规则,因为 kube-proxy 监听的端口在用户空间,这个端口不是服务的访问端口也不是服务的 nodePort,因此需要一层 iptables 把访问服务的连接重定向给 kube-proxy 服务。
iptables与IPVS
从k8s的1.8版本开始,kube-proxy引入了IPVS模式,IPVS模式与iptables同样基于Netfilter,但是ipvs采用的hash表,iptables采用一条条的规则列表。iptables又是为了防火墙设计的,集群数量越多iptables规则就越多,而iptables规则是从上到下匹配,所以效率就越是低下。因此当service数量达到一定规模时,hash查表的速度优势就会显现出来,从而提高service的服务性能
每个节点的kube-proxy负责监听API server中service和endpoint的变化情况。将变化信息写入本地userspace、iptables、ipvs来实现service负载均衡,使用NAT将vip流量转至endpoint中。由于userspace模式因为可靠性和性能(频繁切换内核/用户空间)早已经淘汰,所有的客户端请求svc,先经过iptables,然后再经过kube-proxy到pod,所以性能很差。
ipvs和iptables都是基于netfilter的,两者差别如下:
-
ipvs 为大型集群提供了更好的可扩展性和性能
-
ipvs 支持比 iptables 更复杂的负载均衡算法(最小负载、最少连接、加权等等)
-
ipvs 支持服务器健康检查和连接重试等功能
Iptables模式
iptables 模式是目前默认的代理方式,基于 netfilter 实现。当客户端请求 service 的 ClusterIP 时,根据 iptables 规则路由到各 pod 上,iptables 使用 DNAT 来完成转发,其采用了随机数实现负载均衡。
iptables 模式与 userspace 模式最大的区别在于,iptables 模块使用 DNAT 模块实现了 service 入口地址到 pod 实际地址的转换,免去了一次内核态到用户态的切换,另一个与 userspace 代理模式不同的是,如果 iptables 代理最初选择的那个 pod 没有响应,它不会自动重试其他 pod。
iptables 模式最主要的问题是在 service 数量大的时候会产生太多的 iptables 规则,使用非增量式更新会引入一定的时延,大规模情况下有明显的性能问题。
iptables 因为它纯粹是为防火墙而设计的,并且基于内核规则列表,集群数量越多性能越差。
一个例子是,在5000节点集群中使用 NodePort 服务,如果我们有2000个服务并且每个服务有10个 pod,这将在每个工作节点上至少产生20000个 iptable 记录,这可能使内核非常繁忙。
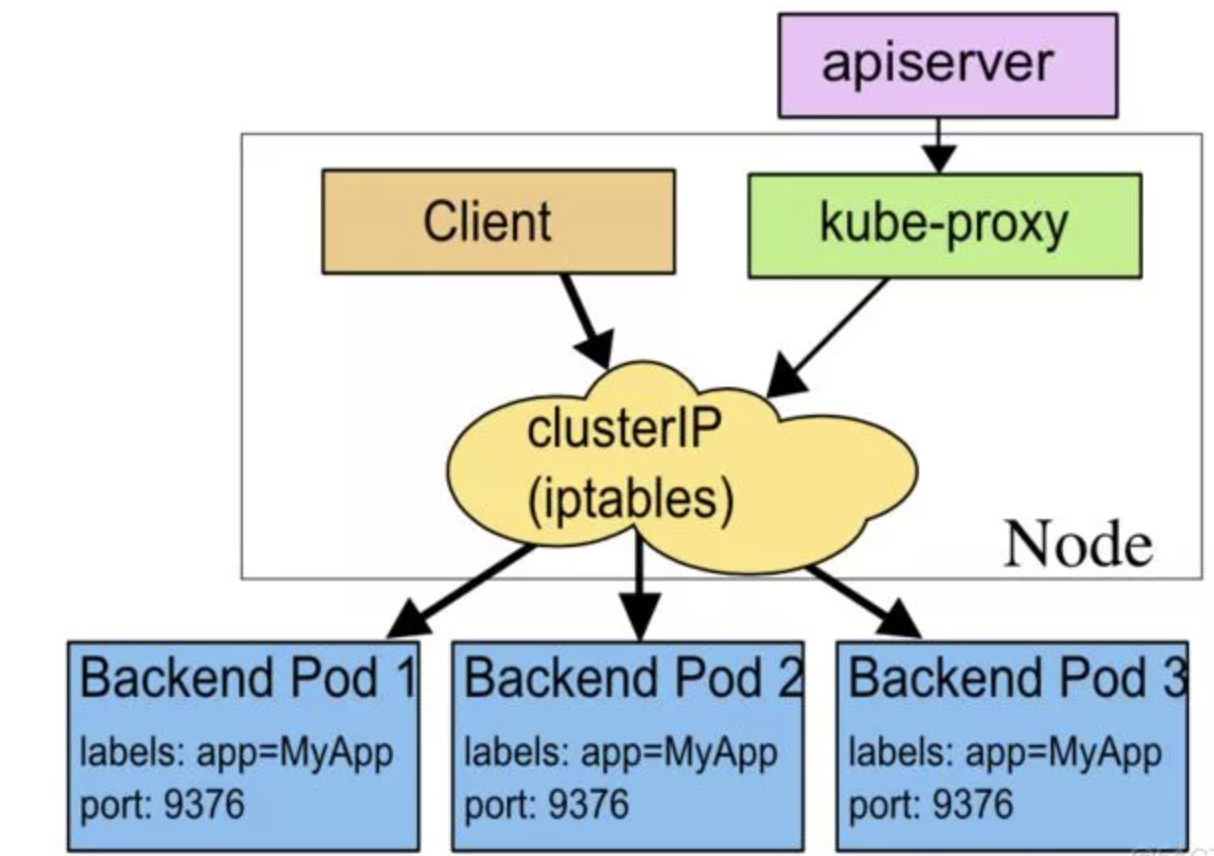
IPVS模式
当集群规模比较大时,iptables 规则刷新会非常慢,难以支持大规模集群,因其底层路由表的实现是链表,对路由规则的增删改查都要涉及遍历一次链表,ipvs 的问世正是解决此问题的,ipvs 是 LVS 的负载均衡模块,与 iptables 比较像的是,ipvs 的实现虽然也基于 netfilter 的钩子函数,但是它却使用哈希表作为底层的数据结构并且工作在内核态,也就是说 ipvs 在重定向流量和同步代理规则有着更好的性能,几乎允许无限的规模扩张。
ipvs 支持三种负载均衡模式:DR模式(Direct Routing)、NAT 模式(Network Address Translation)、Tunneling(也称 ipip 模式)。三种模式中只有 NAT 支持端口映射,所以 ipvs 使用 NAT 模式。linux 内核原生的 ipvs 只支持 DNAT,当在数据包过滤,SNAT 和支持 NodePort 类型的服务这几个场景中ipvs 还是会使用 iptables。
此外,ipvs 也支持更多的负载均衡算法,例如:
-
rr:round-robin/轮询
-
lc:least connection/最少连接
-
dh:destination hashing/目标哈希
-
sh:source hashing/源哈希
-
sed:shortest expected delay/预计延迟时间最短
-
nq:never queue/从不排队
说明
ipvs依赖iptables进行包过滤、SNAT、masquared(伪装)。 使用 ipset 来存储需要 DROP 或 masquared 的流量的源或目标地址,以确保 iptables 规则的数量是恒定的,这样我们就不需要关心我们有多少服务了
如果没有加载并启用ipvs模块,或者没有配置ipvs相关配置,则会被降级成iptables模式。
userspace、iptables、ipvs 三种模式中默认的负载均衡策略都是通过 round-robin 算法来选择后端 pod 的,在 service 中可以通过设置 service.spec.sessionAffinity 的值实现基于客户端 ip 的会话亲和性,service.spec.sessionAffinity 的值默认为"None",可以设置为 "ClientIP",此外也可以使用 service.spec.sessionAffinityConfig.clientIP.timeoutSeconds 设置会话保持时间。kernelspace 主要是在 windows 下使用的
service 的类型
service 支持的类型也就是 kubernetes 中服务暴露的方式,默认有四种 ClusterIP、NodePort、LoadBalancer、ExternelName,此外还有 Ingress,下面会详细介绍每种类型 service 的具体使用场景。
ClusterIP(默认)
ClusterIP 类型的 service 是 kubernetes 集群默认的服务暴露方式,它只能用于集群内部通信,可以被各 pod 访问,其访问方式为:
pod ---> ClusterIP:ServicePort --> (iptables)DNAT --> PodIP:containePort
NodePort
如果你想要在集群外访问集群内部的服务,可以使用这种类型的 service,NodePort 类型的 service 会在集群内部署了 kube-proxy 的节点打开一个指定的端口,之后所有的流量直接发送到这个端口,然后会被转发到 service 后端真实的服务进行访问。Nodeport 构建在 ClusterIP 上,其访问链路如下所示:
client ---> NodeIP:NodePort ---> ClusterIP:ServicePort ---> (iptables)DNAT ---> PodIP:containePort
LoadBalancer
LoadBalancer 类型的 service 通常和云厂商的 LB 结合一起使用,用于将集群内部的服务暴露到外网,云厂商的 LoadBalancer 会给用户分配一个 IP,之后通过该 IP 的流量会转发到你的 service 上。
ExternelName
Externalname类型的Service用于引入集群外部的服务,它通过externalName属性指定外部一个服务的地址,然后在集群内部访问此service就可以访问到外部的服务了
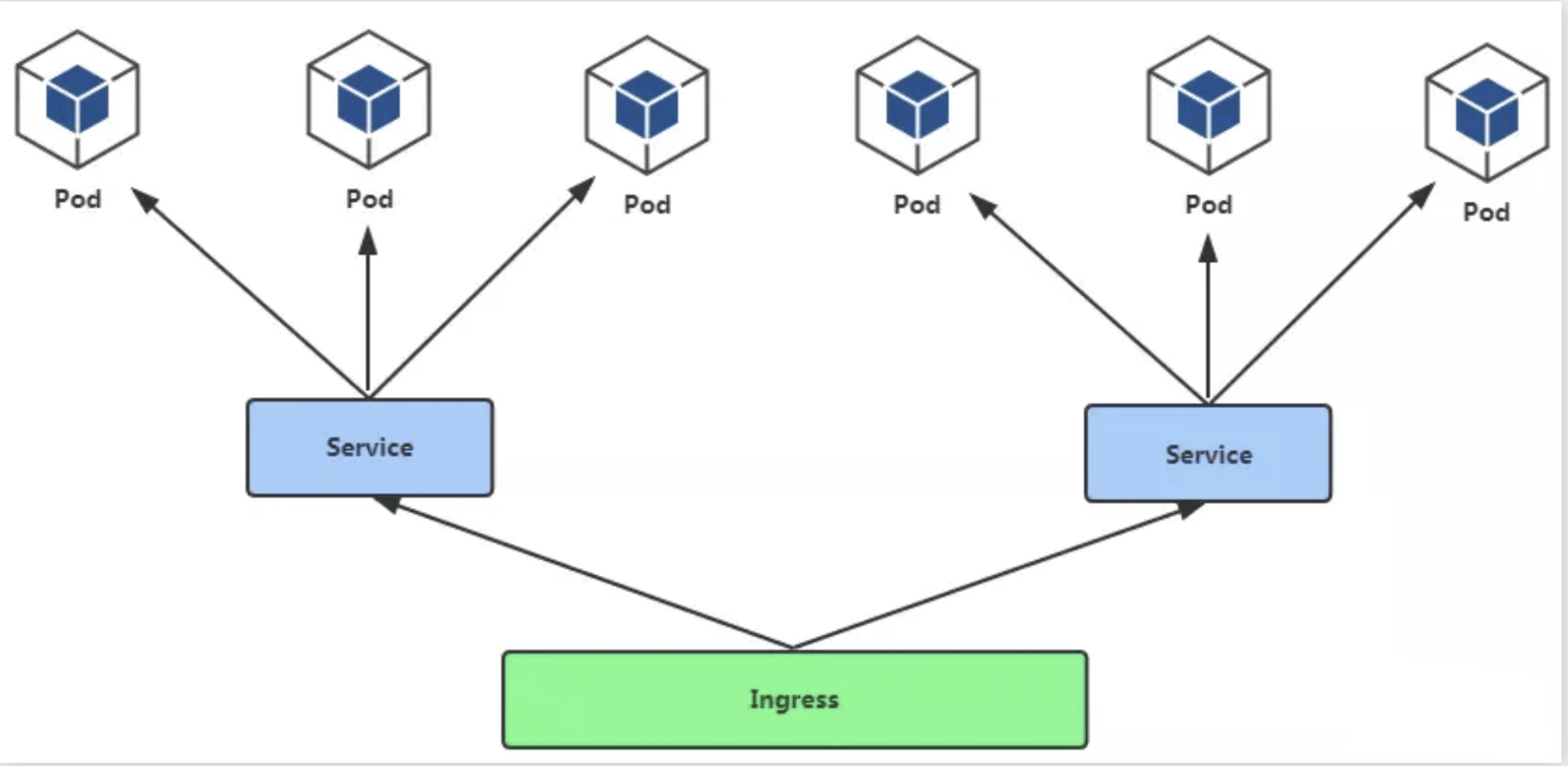
Ingress
Ingress 其实不是 service 的一个类型,但是它可以作用于多个 service,被称为 service 的 service,作为集群内部服务的入口,Ingress 作用在七层,可以根据不同的 url,将请求转发到不同的 service 上。
Ingress 为弥补 NodePort 不足而生 NodePort 存在的不足:
NodePort 存在的不足:
-
一个端口只能一个服务使用,端口需提前规划
-
只支持 4 层负载均衡(iptables 和 ipvs)
扩展:
-
四层:基于 IP 和端口转发
-
七层:HTTP 协议,例如 url、cookie
Pod 与 Ingress 的关系
-
通过 Service 相关联
-
通过Ingress Controller(类iptables 的机制)实现 Pod 的负载均衡
a.支持TCP/UDP 层和HTTP 7层
Ingress Controller

Ingress 暴露应用
http
# http apiVersion: networking.k8s.io/v1beta1 kind: Ingress metadata: name: example-ingress spec: rules: - host: blog.ctnrs.com http: paths: - path: / backend: serviceName: web servicePort: 80
参数解释:
host:域名,类似 nginx 中的server_name path:类似 nginx 中的location serviceName:deployment 中对应的 Service 名称,暴露的项目名称 servicePort:监听端口,类似 nginx 中的listen,Service 的端口(内部端口)
同一域名下,不同的URL路径被转发到不同的服务上
apiVersion: extensions/v1beta1 #新版本是apps/v1 kind: Ingress metadata: name: test-ingress spec: rules: - host: mywebsite.com http: paths: - path: /web backend: serviceName: service2 servicePort: 80 - path: /api backend: serviceName: service1 servicePort: 8081
不同的域名被转发到不同的服务上
apiVersion: extensions/v1beta1 #新版本是apps/v1 kind: Ingress metadata: name: test-ingress spec: rules: - host: foo.bar.com http: paths: - backend: serviceName: service1 servicePort: 80 - host: bar.foo.com http: paths: - backend: serviceName: service2 servicePort: 80
不使用域名的转发规则
apiVersion: extensions/v1beta1 #新版本是apps/v1 kind: Ingress metadata: name: test-ingress spec: rules: - http: paths: - path: /web backend: serviceName: web-service servicePort: 80
注意,使用无域名的Ingress转发规则时,将默认禁用非安全HTTP,强制启用HTTPS. 可以在Ingress的定义中设置一个 annotation " ingress.kubernetes.io/ssl-redirect=false" 来关闭强制启用HTTPS的设置。
service 的服务发现
虽然 service 的 endpoints 解决了容器发现问题,但不提前知道 service 的 Cluster IP,怎么发现 service 服务呢?service 当前支持两种类型的服务发现机制,一种是通过环境变量,另一种是通过 DNS。在这两种方案中,建议使用后者。
环境变量
当一个 pod 创建完成之后,kubelet 会在该 pod 中注册该集群已经创建的所有 service 相关的环境变量,但是需要注意的是,在 service 创建之前的所有 pod 是不会注册该环境变量的,所以在平时使用时,建议通过 DNS 的方式进行 service 之间的服务发现。
DNS
可以在集群中部署 CoreDNS 服务(旧版本的 kubernetes 群使用的是 kubeDNS), 来达到集群内部的 pod 通过DNS 的方式进行集群内部各个服务之间的通讯。
当前 kubernetes 集群默认使用 CoreDNS 作为默认的 DNS 服务,主要原因是 CoreDNS 是基于 Plugin 的方式进行扩展的,简单,灵活,并且不完全被Kubernetes所捆绑。
Service 的使用
ClusterIP 方式
apiVersion: v1 kind: Service metadata: name: my-nginx spec: ports: - port: 80 protocol: TCP targetPort: 8080 selector: app: my-nginx sessionAffinity: None type: ClusterIP clusterIP: 10.105.146.177 #如果不写会自动生成
NodePort 方式
apiVersion: v1 kind: Service metadata: name: my-nginx spec: ports: - nodePort: 30090 port: 80 protocol: TCP targetPort: 8080 selector: app: my-nginx sessionAffinity: None type: NodePort
其中 nodeport 字段表示通过 nodeport 方式访问的端口,port 表示通过 service 方式访问的端口,targetPort 表示 container port。
ExternalName
apiVersion: apps/v1 kind: Service metadata: name: service-externalname namespace: dev spec: type: ExternalName #service的类型 externalName: www.baidu.com #ip或者域名都可以
LoadBalancer
apiVersion: v1 kind: Service metadata: name: example namespace: test spec: type: LoadBalancer LoadBalancerIP: x.x.x.x # 公有云SLB ip selector: key: value ports: - protocol: port: targetPort: nodePort:
Headless service(就是没有 Cluster IP 的 service )
当不需要负载均衡以及单独的 ClusterIP 时,可以通过指定 spec.clusterIP 的值为 None 来创建 Headless service,它会给一个集群内部的每个成员提供一个唯一的 DNS 域名来作为每个成员的网络标识,集群内部成员之间使用域名通信。
apiVersion: v1 kind: Service metadata: name: my-nginx spec: ports: - nodePort: 30090 port: 80 protocol: TCP targetPort: 8080 selector: app: my-nginx type: ClusterIP clusterIP: None #将clusterIP设置为None,即可创建headliness service
您可以选择一种方式赞助本站
支付宝扫一扫赞助
微信钱包扫描赞助
赏