
elasticsearch实现数据冷热分离的目的主要是为了方便针对旧数据和新数据的分离,比如只保留7天的数据,但是7天之前的数据查看的少了,但是为了方便后期使用,所以也做保留,但是却很少查看,这个时候如果不做冷热分离就会对整个集群的资源使用有很大的浪费,而且也会影响elasticsearch集群的访问速度,所以,针对elasticsearch集群做冷热处理,常用的数据放到配置稍微高一点的节点上,不常用的数据放到配置低的节点上,这样针对常用的数据自动过期放到冷处理节点上,看一下配置吧。
注意
以前es2.x版本配置elasticsearch.yml 里的node.tag: hot这个配置不生效了 被改成了这个 node.attr.box_type: hot
架构
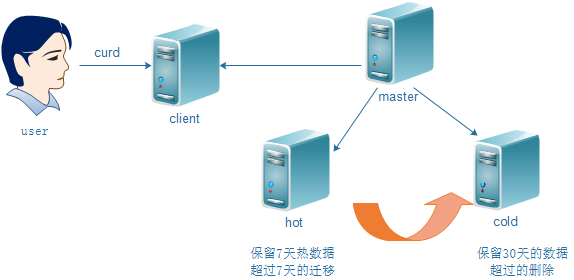
master节点的es配置
master节点: [root@n1 ~]# cat /usr/local/elasticsearch/config/elasticsearch.yml cluster.name: elk node.master: true node.data: false node.name: 192.168.2.11 #node.attr.box_type: hot #node.tag: hot path.data: /data/es path.logs: /data/log network.host: 192.168.2.11 http.port: 9200 transport.tcp.port: 9300 transport.tcp.compress: true discovery.zen.ping.unicast.hosts: ["192.168.2.11"] cluster.routing.allocation.disk.watermark.low: 85% cluster.routing.allocation.disk.watermark.high: 90% indices.fielddata.cache.size: 10% indices.breaker.fielddata.limit: 30% http.cors.enabled: true http.cors.allow-origin: "*" #################################分割线################################## - client节点(这里就不配置了) node.master: false node.data: false
hot节点
- hot节点 [root@n2 ~]# cat /usr/local/elasticsearch/config/elasticsearch.yml cluster.name: elk node.master: false node.data: true node.name: 192.168.2.12 node.attr.box_type: hot path.data: /data/es network.host: 192.168.2.12 http.port: 9200 transport.tcp.port: 9300 transport.tcp.compress: true discovery.zen.ping.unicast.hosts: ["192.168.2.11"] cluster.routing.allocation.disk.watermark.low: 85% cluster.routing.allocation.disk.watermark.high: 90% indices.fielddata.cache.size: 10% indices.breaker.fielddata.limit: 30% http.cors.enabled: true http.cors.allow-origin: "*"
cold节点
- cold节点 [root@n3 ~]# cat /usr/local/elasticsearch/config/elasticsearch.yml cluster.name: elk node.master: false node.data: true node.name: 192.168.2.13 node.attr.box_type: cold path.data: /data/es network.host: 192.168.2.13 http.port: 9200 transport.tcp.port: 9300 transport.tcp.compress: true discovery.zen.ping.unicast.hosts: ["192.168.2.11"] cluster.routing.allocation.disk.watermark.low: 85% cluster.routing.allocation.disk.watermark.high: 90% indices.fielddata.cache.size: 10% indices.breaker.fielddata.limit: 30% http.cors.enabled: true http.cors.allow-origin: "*"
我hot节点打了tag
node.attr.box_type: cold
创建一个template(这里我用kibana来操作es的api)
PUT _template/test
{
"index_patterns": "test-*",
"settings": {
"index.number_of_replicas": "0",
"index.routing.allocation.require.box_type": "hot"
}
}
test-*
以test-2018.07.05索引为例,将它从hot节点迁移到cold节点
kibana里操作:
PUT /test-2018.07.05/_settings
{
"settings": {
"index.routing.allocation.require.box_type": "cold"
}
}
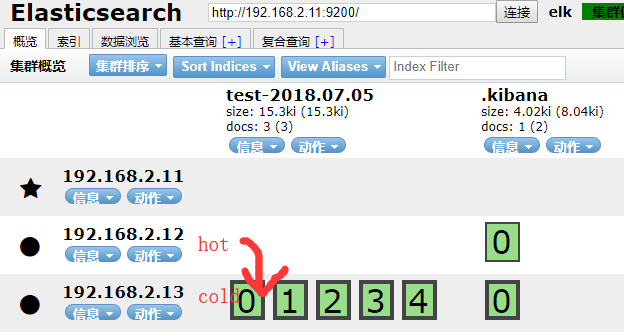
生产中可能每天,或每h,生成一个index.
test-2018.07.01 test-2018.07.02 test-2018.07.03 test-2018.07.04 test-2018.07.05 ...
如我在hot节点只保留7天的数据,7天以前的索引我匹配到, 每天晚上执行以下迁移命令即可.可以参考:https://www.wulaoer.org/?p=2691
1.为了提高吞吐量
path.data:/data1,/data2,/data3,/data4,/data5 可以每个目录挂一块盘
2.如果有10台hot节点,可以设置10个shards
logstash测试
nput { stdin { } }
output {
elasticsearch {
index => "test-%{+YYYY.MM.dd}"
hosts => ["192.168.2.11:9200"]
}
stdout {codec => rubydebug}
}
/usr/local/logstash/bin/logstash -f logstash.yaml --config.reload.automatic
关于es的index template
关于
es数据入库时候都会匹配一个index template,默认匹配的是logstash这个template
template大致分成setting和mappings两部分
-
settings主要作用于index的一些相关配置信息,如分片数、副本数,tranlog同步条件、refresh等。
-
mappings主要是一些说明信息,大致又分为all、source、prpperties这三部分: https://elasticsearch.cn/article/335
根据index name来匹配使用哪个index template. index template属于节点范围,而非全局. 需要给某个节点单独设置index_template(如给设置一些特有的tag).
您可以选择一种方式赞助本站
支付宝扫一扫赞助
微信钱包扫描赞助
赏